Hadoop
下载地址
下载地址


本地下载文件大小:203MB
Hadoop是一个由Apache基金会所开发能够让用户轻松架构和使用的大规模数据处理平台,是处理、存储和分析海量的分布式、非结构化数据的开源框架。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,并且它的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。Hadoop具备可靠、高效、可伸缩等特点,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。有需要使用Hadoop的朋友快通过kkx分享的地址来获取吧!
1. 高可靠性。
Hadoop按位存储和处理数据的能力值得人们信赖。
2. 高扩展性。
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3. 高效性。
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4. 高容错性。
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5. 低成本。
与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop2.7.1的部署
机器环境:
操作系统:CentOS 6.4 64位系统
Hadoop版本:hadoop-2.7.1,在CentOS下自行编译后的64位版本。
1、首先下载安装包tar zxvf hadoop-2.7.1.tar.gz
2.在虚拟机中解压安装包

3.安装目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
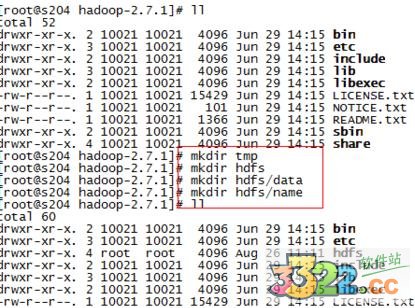
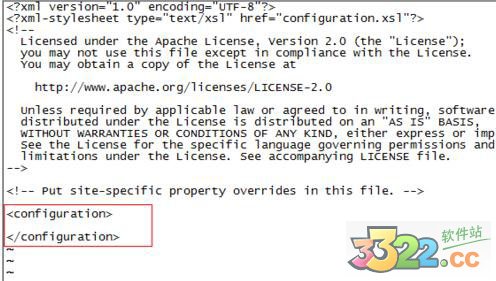
4、修改/home/yy/hadoop-2.7.1/etc/hadoop下的配置文件
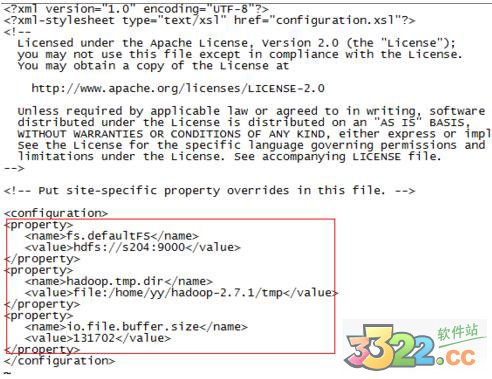
修改core-site.xml,加上
fs.defaultFS
hdfs://s204:9000
hadoop.tmp.dir
file:/home/yy/hadoop-2.7.1/tmp
io.file.buffer.size
131702
5.修改hdfs-site.xml,加上
dfs.namenode.name.dir
file:/home/yy/hadoop-2.7.1/dfs/name
dfs.datanode.data.dir
file:/home/yy/hadoop-2.7.1/dfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
s204:9001
dfs.webhdfs.enabled
true

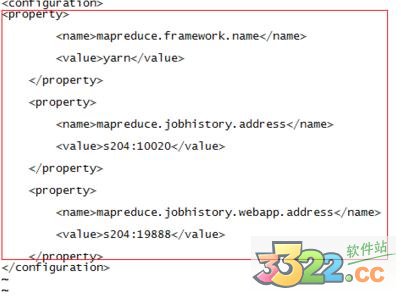
6.修改mapred-site.xml,加上
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
s204:10020
mapreduce.jobhistory.webapp.address
s204:19888
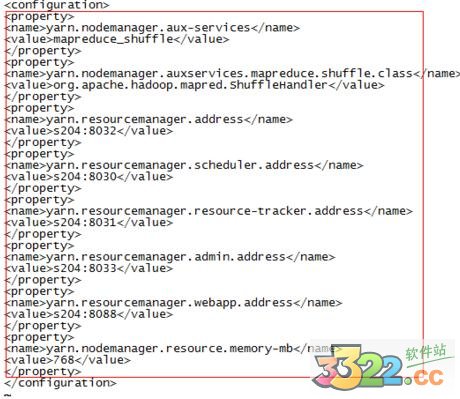
7.修改yarn-site.xml,加上
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
s204:8032
yarn.resourcemanager.scheduler.address
s204:8030
yarn.resourcemanager.resource-tracker.address
s204:8031
yarn.resourcemanager.admin.address
s204:8033
yarn.resourcemanager.webapp.address
s204:8088
yarn.nodemanager.resource.memory-mb
768
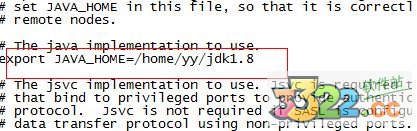
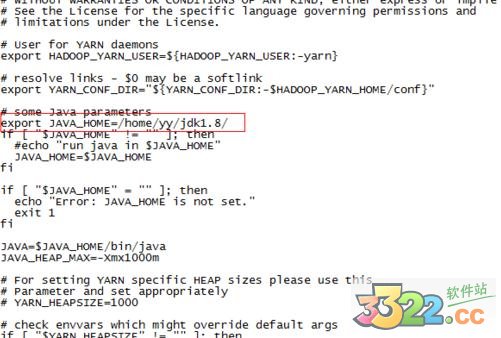
8、配置/home/yy/hadoop-2.7.1/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,否则启动时会报error
export JAVA_HOME=/home/yy/jdk1.8
9.配置/home/yy/hadoop-2.7.1/etc/hadoop目录下slaves
加上你的从服务器,我这里只有一个s205
配置成功后,将hadhoop复制到各个从服务器上
scp -r /home/yy/hadoop-2.7.1 root@s205:/home/yy/

10.主服务器上执行bin/hdfs namenode -format
进行初始化
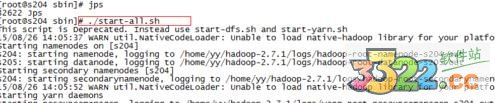
sbin目录下执行 ./start-all.sh
可以使用jps查看信息
停止的话,输入命令,sbin/stop-all.sh
11.这时可以浏览器打开s204:8088查看集群信息啦
到此配置完成,如图:
Hadoop V2.7.1免费版203MB返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知
 91U盘助手 V3.5无广告版
91U盘助手 V3.5无广告版 Daemon Tools虚拟光驱(支持win7、win10) V10.9汉化破解版
Daemon Tools虚拟光驱(支持win7、win10) V10.9汉化破解版 鸿业暖通空调软件 v8.0完美破解版
鸿业暖通空调软件 v8.0完美破解版 lockdir v5.75 绿色免费版
lockdir v5.75 绿色免费版 小点阵体 V6100.00官方版
小点阵体 V6100.00官方版 971款电子表格模板(Excel模板)
971款电子表格模板(Excel模板)  ASSSDBenchMark(硬盘测速) 绿色版
ASSSDBenchMark(硬盘测速) 绿色版 迅雷看看播放器 v6.1.1.603官方版
迅雷看看播放器 v6.1.1.603官方版