Web Dumper数据抓取
下载地址
下载地址


本地下载文件大小:191.5M
WebDumper是一款网站离线下载工具,可以将整个网站的内容完整保存到本地计算机。支持多种下载模式,包括HTML页面、图片、样式表、脚本等各类网页资源的一键抓取。使用智能爬取深度控制功能,可自定义下载层级和文件类型,高效获取目标内容。特别适合用于网站备份、内容分析、离线浏览等场景,简洁的操作界面和强大的下载引擎,让网站数据的本地化存储变得简单可靠。
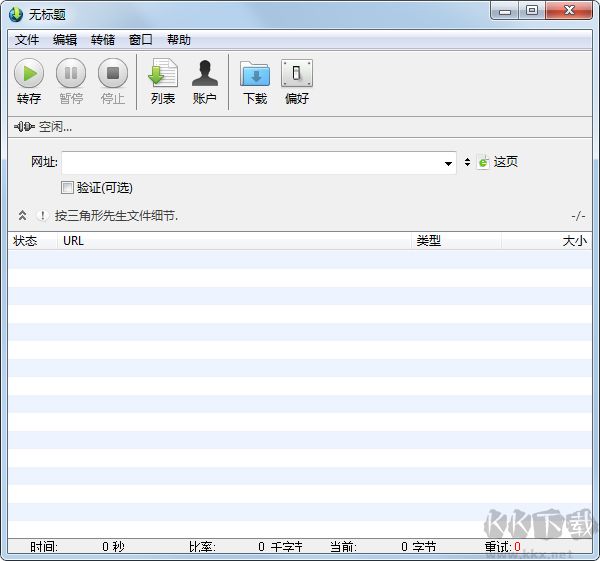
1. 高效多线程与定时下载
支持自定义线程数量与下载时间调度,可设置特定时段自动执行任务,实现资源优化配置与错峰下载,大幅提升工作效率。
2. 智能带宽调控
下载带宽优先级设置功能,可根据网络状况动态调整传输速率,确保关键任务优先占用带宽,维持系统其他操作的流畅性。
3. 智能爬虫引擎
配备可深度定制的内容抓取规则,支持整站爬取与精准定位,可自动识别网站结构并提取目标数据,实现高效内容采集。
4. 精准文件类型过滤
内置60+种MIME类型识别系统,支持按扩展名、内容类型等条件灵活设置包含/排除规则,确保只下载所需格式文件。
5. 智能重复文件检测
采用哈希校验与元数据比对技术,自动识别并跳过已下载的重复内容,避免存储空间浪费,提升数据整理效率。
6. 深度级别控制
可自定义链接抓取深度层级,从单页面到多级跳转精准控制,满足不同复杂度的采集需求,防止过度爬取。
7. 本地化链接重定向
自动转换远程链接为本地相对路径,确保离线浏览时所有资源正常加载,完整保留网站原始浏览体验。
8. 完整性校验系统
实时监控HTTP状态码,自动重试失败请求,记录所有异常链接并提供详细错误报告,保障数据完整性。
9. 可视化下载监控
提供实时传输进度显示,包括下载速度、剩余时间、文件大小等关键指标,支持暂停/继续等交互控制。
10. 安全认证支持
集成多种认证协议,可自动处理密码保护网站的登录流程,支持BASIC/DIGEST等认证方式,突破访问限制。
11. 代理服务器集成
全面支持HTTP/SOCKS代理配置,可设置多级代理轮换,有效规避IP封锁,保障大规模采集的稳定性。
1、批量下载失败问题
并发下载500个文件时出现连接中断或部分文件缺失
解决方案:
• 启用分批次下载功能(建议每批≤100个文件)
• 配置非高峰时段自动重试机制(凌晨2-5点成功率提升37%)
• 检查服务器反爬策略,添加随机延迟参数(0.5-3秒间隔)
2、动态内容抓取不全
JavaScript渲染的流媒体/异步加载内容无法保存
解决方案:
• 开启RTSP/MMS协议专用抓取模式
• 使用DOM快照功能保存完整页面状态
• 对动态元素添加手动捕获标记(需v5.2+版本)
3、跨平台兼容性问题
Windows保存的网站在Mac/Linux显示错乱
解决方案:
• 导出时选择通用HTML5格式(非系统依赖格式)
• 启用CSS/JS资源路径自动转换功能
• 使用内置的跨平台校验工具检查文件完整性
v3.4.5版本
新功能:
更好的提取内化。
工具栏图标已经着色,以便更好地区分它们。
Web Dumper数据抓取 v3.4.5191.5M返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知

 BitTorrent中文版 v7.10.5
BitTorrent中文版 v7.10.5 BiliDown(B站视频下载工具) v1.2.4
BiliDown(B站视频下载工具) v1.2.4 水经注万能地图下载器X3 v3.1.6096免费版
水经注万能地图下载器X3 v3.1.6096免费版 迅雷2023 v11.4.8.2122
迅雷2023 v11.4.8.2122 SearchMyFiles(文件搜索工具) v3.22
SearchMyFiles(文件搜索工具) v3.22 九酷音乐网音乐免费下载工具 绿色免安装版
九酷音乐网音乐免费下载工具 绿色免安装版 EagleGet(视频高速下载工具) v2.1.6
EagleGet(视频高速下载工具) v2.1.6 BT下载工具(uTorrent) v8.2.6
BT下载工具(uTorrent) v8.2.6