火车头数据采集平台
下载地址
下载地址


本地下载文件大小:29.65MB
火车头数据采集平台是一款用于搜索获取全网数据的网络辅助工具,可以灵活迅速地抓取网页中大量非结构化的文本,图片等资源信息,通过一系列的分析处理,准确挖掘出所需数据。并可以选择发布到网站后台、导入数据库或者保存在本地Excel,Word等格式的文件中。火车采集器是目前最受欢迎的网页数据采集软件,有需要进行采集操作的用户快来获取吧!
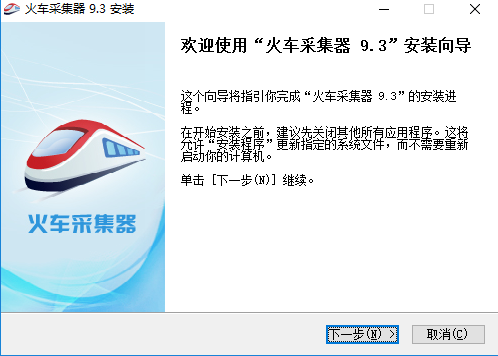
1、等待火车采集器下载完成,然后解压缩并双击exe文件,进入安装向导,点击下一步。
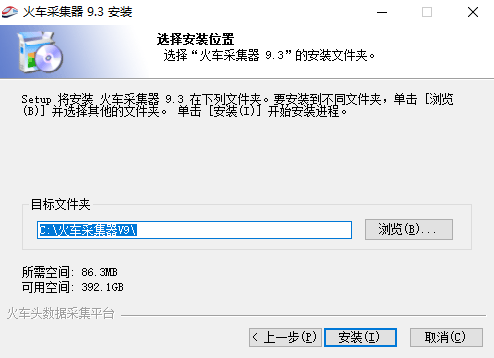
2、点击【浏览】设置软件的安装位置,然后点击【安装】。
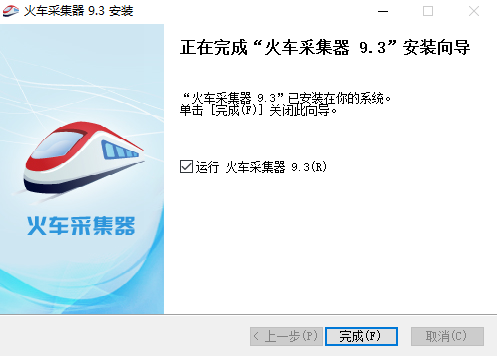
3、稍等片即可完成安装,勾选【运行 火车采集器 9.3】选项,点击【完成】即可运行。
1、无限级多张采集,能够完成无尽深层的采集
2、每日任务序列运作管理方法,适用Cron关系式
3、无限级排序任务管理,每日任务垃圾回收站功能
4、RSS详细地址采集功能
5、列表页分页查询采集获得功能
6、列表页额外主要参数获得功能
7、列表页及标识XPath数据可视化获取功能
8、标识纯正则替换功能
9、Http插口查询运作状况
10、导出来纪录为单独或好几个Txt、html文档
11、标识间随意搭配功能
12、对于标识內容再次推送Http要求功能
13、无限级列表网站地址采集
14、从Http头信息内容中读取数据
15、题目內容文章正文获取功能
16、Aspx列表分页查询自鉴别
17、多网址站群系统式web公布
18、导出来纪录为Word格式
19、导出来全部纪录为Excel格式
20、应用任意二级(适用Socket代理)
21、多拓展间数据传输功能
22、免费下载的图片全自动加加强型图片水印功能
23、Ocr鉴别(图片转换为文本)
24、Http插口管理方法采集器运作
25、Mongodb数据库储存数据信息
26、主从关系网络服务器分布式系统采集
1.在程序主界面中,点击“新建”下拉箭头,从中选择“任务”项。
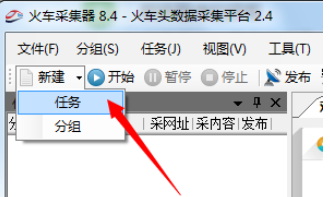
2.在弹出的窗口中,输入“任务名”,同时点击“起始网址”栏目右侧的“添加”按钮。
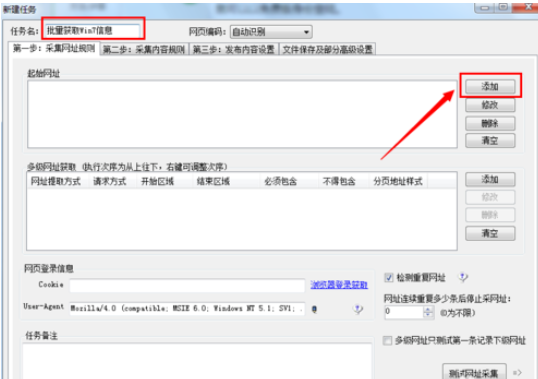
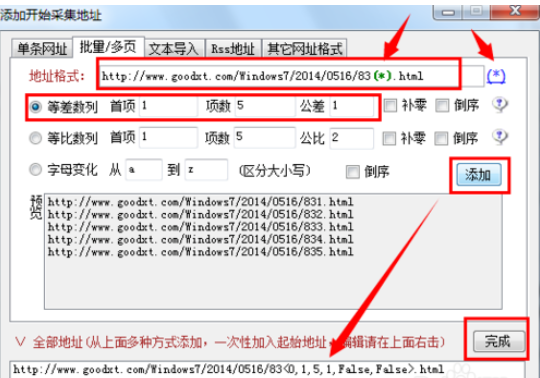
3.接下来就极为重要的一步,就是对要进行采集的网站进行分板,对所采取的网站中各片文章的URL进行综合分析并找出规律,最后按如图进行填写。
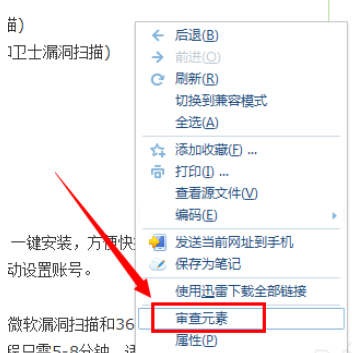
4.然后切换至“第二步:采集内容规则”选项卡中,我们需要对网页内容进行分板。在此以“搜狗浏览器”为例,右击要进行分析的网页,从弹出的菜单中选择“审查元素”项。
5.在“开发式模式”界面中,点击“选择页面中的一个元素去透视”按钮,接着点击“标题”内容,此时就可以在“开发者”窗口中显示标题所对应的标签,此例为“h2"。
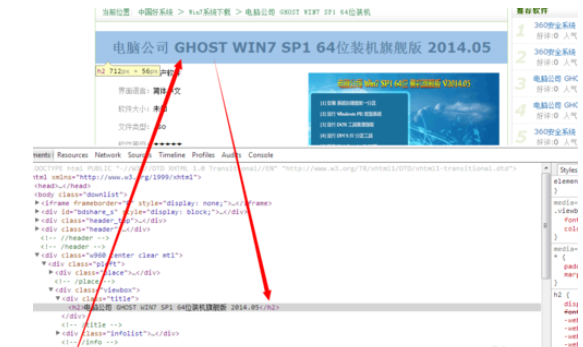
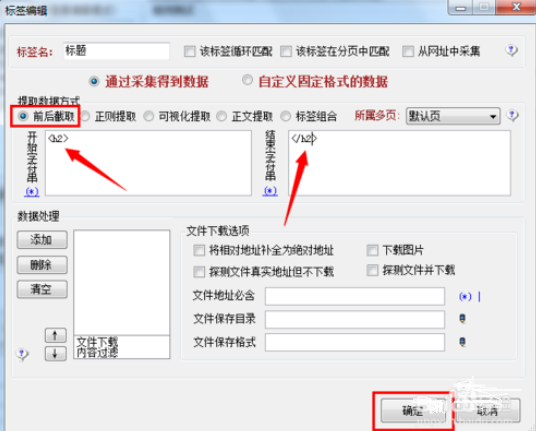
6.接下来在”采集内容规则“界面中,点击“添加”按钮来添加“标题”项,或者直接双击“标题”项进行修改。在弹出的界面中,勾选”前后截取“,将设置前后辍分别为"“、”".
7.利用同样的方法添加其它采集内容的规则。切换至“第三步:发布内容设置”选项卡,勾选“启用 方式二”,并进行如图设置。
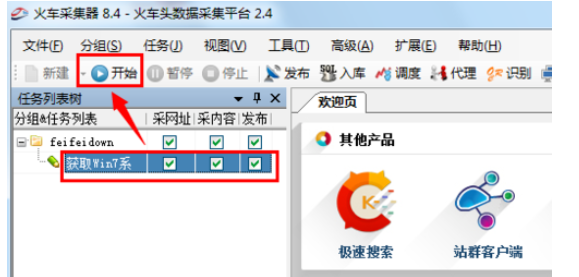
8.最后从任务列表中,勾选要采集的内容,点击“开始”按钮就可以按规则采集网站中的网页内容啦。
数据转换
数据采集下来后可选择保存到sqlite、mysql、sqlserver三种类型的数据库中。
默认保存为sqlite数据库,可转换为其他类型,其中sqlite是可以保存在本地数据库的。
mysql、sqlserver既可以保存在本地数据库,也可以保存到远程数据库。
工具菜单--数据转换
如需转换原有数据库请勾选“转换内容库”,否则数据库内容将被清空。
分组右键功能
在分组上右击,支持导入任务,导出分组,导入分组等。
导入任务:分组上右击--导入任务,可以导入.ljobx后缀的任务。
导出分组:分组上右击--导出分组,批量导出任务分组,可以导出.lgrp后缀的分组。
导入分组:分组上右击--导入分组,批量导入任务分组,可以导入.lgrp后缀的分组。
采集规则
起始网址
采集规则制作的第一步骤,点击向导添加,①→②,出现如图界面。
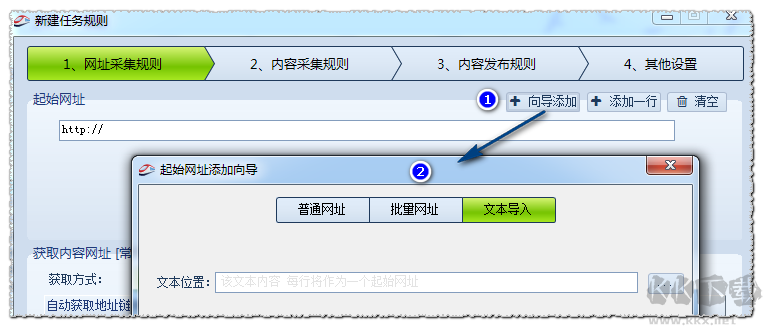
分3种方式:普通网址,批量网址,文本导入。
获取内容网址
有常规模式和高级模式两种。
1.常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页A链接。
它有2种方式:a.自动获取地址链接 b.手动设置规则获取。
2.高级模式:该模式对0级,多级,POST类型网址的抓取有效。
即起始网址就是内容页网址;
或者需要对多级列表网址采集才能得到最终内容页链接;
或者是post网址类型抓取等情况下使用高级模式。
0级及多级网址获取
起始网址就是内容页网址,直接采集起始网址里的内容。
何为多级?
即有多级列表,需要设置多级网址步骤后,才能得到最终内容页链接。
列表上下页分页
对于设置列表分页,下图的起始网址--批量网址设置是最常见也是最常用的。
登录采集
登录信息设置: 对于部分需要登录的网站,需要设置此项。
1.优化标签数据处理中字符替换。
2.对文件探测无效导致文件下载失败问题优化。
3.处理用户名包含特殊符号不能登录问题。
4.修复数据管理批量操作数据有异常弹窗提示。
5.修复二级代理卡死问题。
6.完善自动获取cookie失败问题。
7.发布到word,自动转义"<"、">"为"<"、">"。
8.修复:勾选发布选项,采集最大数无效。
9.修复oracle链接问题。
10.支持oss存储。
11.修复:下载地址后面有斜杠,下载文件时无后缀名。
火车头数据采集平台 V9.3破解版29.65MB返回顶部
Copyright © 2009-2023 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知
 火车头采集器免费版 V9无限制版本
火车头采集器免费版 V9无限制版本 PhotoImpact网页编辑器 V10中文破解版
PhotoImpact网页编辑器 V10中文破解版 网页三剑客绿色破解版
网页三剑客绿色破解版  网站搜索工具(遍历网站二级页面) V1.0吾爱破解版
网站搜索工具(遍历网站二级页面) V1.0吾爱破解版 Xenu(网站死链检测软件) v2.2.8 绿色最新版
Xenu(网站死链检测软件) v2.2.8 绿色最新版 XenuLinkSleuth死链检测工具 v1.3.8
XenuLinkSleuth死链检测工具 v1.3.8![免费分销系统源码[欧极分销源码] v6.0正式版](http://www.kkx.net/uploadfile/2021/0604/20210604084506881.png) 免费分销系统源码[欧极分销源码] v6.0正式版
免费分销系统源码[欧极分销源码] v6.0正式版 名风SEO关键词优化工具 v22.1破解版
名风SEO关键词优化工具 v22.1破解版